Gestión del Dato en entornos IoT
El pasado 28 de enero, Mistral dio una charla acerca de la gestión de los datos en entornos IoT, dentro del ciclo de conferencias titulado “Hablemos del Dato” ofrecido por ANBAN (Asociación Nacional de Big Data y Analytics).
Para quien no pudiera asistir, en este enlace podéis acceder a la grabación de la misma.
En este artículo vamos a resumir las cuestiones clave que se trataron ese día.
Casos de Uso
Industria 4.0 es la transformación digital aplicada a la industria de producción. Dicha transformación incluye, entre otras cosas, la sensorización de las máquinas de las líneas de producción. Con los datos obtenidos por estos sensores, hay un par de casos de uso que son lo que en primera instancia se empieza a obtener valor de los datos:
- Mantenimiento Preventivo: Consiste en predecir cuándo una máquina va a fallar. Sabiendo esto, se pueden programar paradas técnicas para mantenimiento, evitando paradas inesperadas en la producción.
- Reducción de Mermas: Reducir pérdida de materias primas y costes de producción, detectando con antelación cuándo el proceso productivo va a ser erróneo. Este conocimiento nos permite anticiparnos y tomar las medidas correctivas necesarias mientras el proceso está en marcha, evitando la fabricación de algo que habría que desechar.
Características del Dato en entornos IoT
Los datos de este tipo de proyectos tienen unas características muy concretas, entre las que destacan:
- Velocidad: Hay múltiples sensores emitiendo datos cada pocos segundos o milisegundos, 24/7.
- Volumen: Esto genera un gran volumen de datos, pues necesitaremos además guardar un histórico de varios daños para poder hacer predicciones precisas.
- Variedad: Los datos emitidos por los sensores vendrán típicamente en ficheros, por lo que estaríamos tratando con datos no estructurados (semiestructurados, en realidad).
- (Nótese las 3 clásicas V’s que definen un proyecto de Big Data)
- Estructura: Hay que estructurar los datos que llegan de manera semiestructurada y cruzarlos con datos estructurados almacenados previamente (histórico de errores, modelos de máquinas, …, metadatos en general).
- Almacenamiento: Hay que gestionar el almacenamiento de un gran volumen de datos, estructurados y no estructurados, y hacerlo de manera que el rendimiento del sistema sea correcto y el coste del almacenamiento sea óptimo.
Retos que resolver
En un proyecto IoT hay una serie de problemas (llamémosle mejor “retos”), que nos vamos a encontrar y para los que hay que tener preparada una solución. Algunos de los principales son:
- Velocidad de captura de los datos, gestión del almacenamiento de los mismos y el rendimiento de todo el sistema en su conjunto.
- El entorno más adecuado para desarrollar estos proyectos es el cloud, por varios motivos, pero principalmente, por simplificar la implantación y desarrollo del proyecto, por las múltiples herramientas que ofrece, por la capacidad para escalar el proyecto y por el control del coste.
- Control de la pérdida de datos, así como la validación de la corrección de los datos (sensores que funcionan mal o no lo hacen)
- Seguridad: Algo que cada día es más importante y está más presente en cualquier tipo de proyecto.
- Skills del equipo de desarrollo: Estos proyectos requieren de múltiples skills técnicos, pues se unen distintas áreas: definición de la arquitectura del proyecto, desarrollo en cloud y administración de todo el sistema, manejo de grandes conjuntos de datos, modelado óptimo de los datos en las distintas etapas, automatización de la “tubería” por la que el dato discurre desde que sale de un sensor hasta que acaba almacenado en una base de datos.
El viaje del Dato
En el siguiente diagrama simplificado, podemos ver las etapas por las que pasa un dato desde el sensor hasta su destino final.
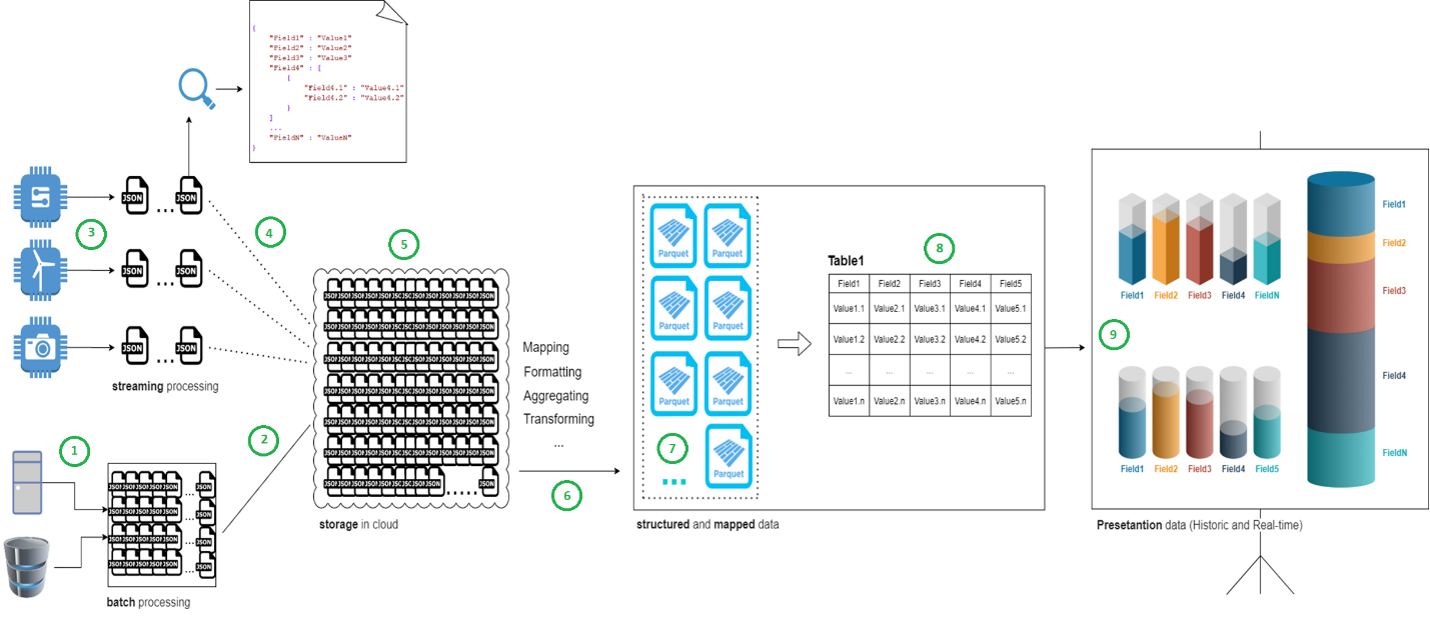
- Posiblemente se disponga de un histórico de datos que se ha acumulado a lo largo de los últimos meses o años, como paso previo al inicio de un proyecto de tratamiento de los mismos.
- Hay que diseñar un proceso batch, que será ejecutado una vez, y que se encargará de cargar los datos en una primera zona de almacenamiento temporal.
- Por otro lado, tenemos la parte streaming del proyecto, los sensores, generando datos en tiempo real.
- Estos datos, que aquí han sido representados como ficheros JSON, deben ser capturados (PLC, Raspberry o algún otro elemento similar) y transmitidos a la nube, a un espacio inicial de almacenamiento.
- Ésta es la primera zona de almacenamiento en la nube, donde llegan los datos de los sensores, embebidos en ficheros (JSON, CSV, XML, etc.) Aquí los datos se recopilan tal cuál llegan, sin tratar.
- Se hace un procesamiento de los mismos (limpieza de datos, agregación, descarte, transformación de datos…cada proyecto puede requerir distintas operaciones) y se almacenan con un formato óptimo para su explotación. Hay distintas opciones (7 y 8)
6bis. Los datos almacenados en 5, una vez han sido procesados, pueden almacenarse, de manera comprimida, en un sistema de almacenamiento económico, por si hicieran falta en el futuro.
- El formato original de los ficheros puede transformarse en otros formatos que ocupan menos espacio (avro, orc, parquet; en una prueba que hicimos en Mistral, ficheros de 300K en formato JSON pasaron a ocupar 30K en formato parquet) y que añaden metadatos.
Sobre estos ficheros pueden ejecutarse directamente queries SQL, usando las herramientas adecuadas, como por ejemplo AWS Athena, de manera que podríamos gestionar los datos posteriormente como si estuvieran almacenados en una base de datos SQL.
- Si por cuestiones de rendimiento fuese necesario que los datos estén almacenados en base de datos (lo normal es que lo sea a partir de cierto momento), podemos transformar los datos semiestructurados en datos estructurados y cargarlos en una base de datos.
- Finalmente, tenemos los datos a disposición de las herramientas que van a extraer valor de los mismos, bien a través de visualizaciones o con algoritmos de machine learning para hacer predicciones.
Cómo empezar un proyecto IoT
A grandes rasgos, hay cuatro aspectos fundamentales para tener en cuenta, algunos de los cuales son aplicables a cualquier tipo de proyecto.
- Poner el ROI como principio y fin del proyecto. A la hora de elegir el tipo de proyecto, su alcance, las etapas en que va a desarrollarse, hay que tener presente qué problema queremos solucionar, qué beneficio económico nos va a proporcionar y cómo vamos a medirlo. Afortunadamente, en este tipo de proyectos es relativamente sencillo medir el ROI (es fácil saber la reducción del número de horas que la cadena de producción ha estado parada por un error inesperado o la reducción en las mermas).
- ¡Sensorizar ya! Estos proyectos necesitan un histórico de datos previo, para que los algoritmos de machine learning puedan ser entrenados. Por ello, previo al comienzo de un proyecto de este tipo, es necesario (cuanto menos, muy recomendable) que las máquinas hayan sido sensorizadas y ya dispongamos de varios meses (cuantos más mejor) de datos.
- Registrar datos de errores anteriores. Los algoritmos de machine learning no solo necesitan los datos de los sensores, también necesitan saber cuándo se han producido fallos en el sistema, para poder relacionar los fallos con los datos de los sensores en esos momentos y en las horas y días previos. También ayuda mucho el saber no solo que hubo un error, sino qué tipo de error fue. Sin este tipo de información registrada, no hay proyecto.
- Empezar por algo pequeño. Lo ideal es sensorizar la fábrica entera, como hemos comentado en el punto 2. Pero a la hora de empezar a implantar los algoritmos predictivos, se puede empezar a trabajar con una máquina o con una línea de producción, para reducir el alcance, delimitar los problemas y aprender del sistema. Cuando se consigan buenos resultados, es fácil y rápido implantar los algoritmos predictivos para el resto de la fábrica.
Conclusiones
- Es un tipo de proyecto que, aunque no es sencillo, es realizable, y la prueba es que cada vez hay más empresas que los están llevando a cabo.
- Es necesario disponer de un histórico de datos de sensores y de errores previos.
- Es altamente recomendable que el proyecto se realice utilizando tecnologías cloud.
- Hay que tener muy presente los skills técnicos necesarios, a la hora de elegir el equipo de desarrollo.
- Para abordar el proyecto, hay que tener el ROI presente y avanzar paso a paso.
- En este artículo no se menciona, aunque sí se hizo en la charla: nuestras empresas compiten no solo contra otras empresas de su entorno, sino contra empresas internacionales, muchas de ellas ubicadas en países donde los costes son mucho menores y apenas existe regulación medioambiental (que encarece los costes productivos). Por tanto, la única manera de competir con esas empresas es aumentando la eficiencia, la productividad, el rendimiento, la calidad del producto. Estos proyectos de IoT vienen para ayudar a conseguir todo esto.
- Es un camino largo y, quien no haya empezado a recorrerlo, debe hacerlo ya.
Esperamos que hayáis encontrado este artículo muy interesante. Como mencionábamos al principio, si queréis ver la sesión completa, en este enlace podéis hacerlo.
Gracias por el tiempo dedicado a leer este artículo. Volveremos pronto.
Últimas entradas